[项目010] 树的的综合应用 隐藏答案 | 返回首页
作者:欧新宇(Xinyu OU)
当前版本:Release v1.0
开发平台:gcc 13.1.0, g++ 13.1.0, gdb 13.2
运行环境:Intel Core i7-13700KF CPU 3.4GHz, 32GB RAM
本教案所涉及的数据及代码仅用于教学和交流使用,请勿用作商用。
最后更新:2023年11月15日
作业要求:将【课后作业】的题目及程序代码整理成实验报告,并以PDF格式,或直接拍照上传到【雨课堂】(不要使用word文档进行上传)。
【课后作业】
1. 将下面一个由三棵树组成的森林转换为二叉树。
🏷️Project01001A
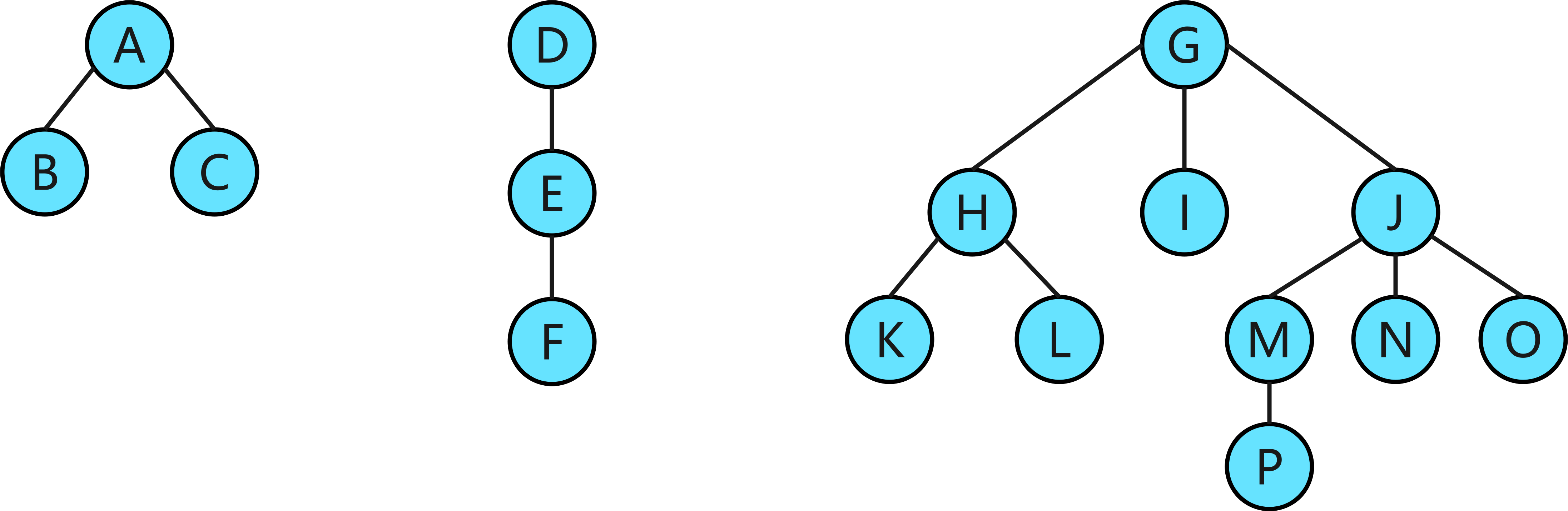
答案及解析:
根据“左孩子右兄弟”转换原则,将森林转换为二叉树的过程主要包括:整形、连线、去线、整形。
🏷️Project01001B
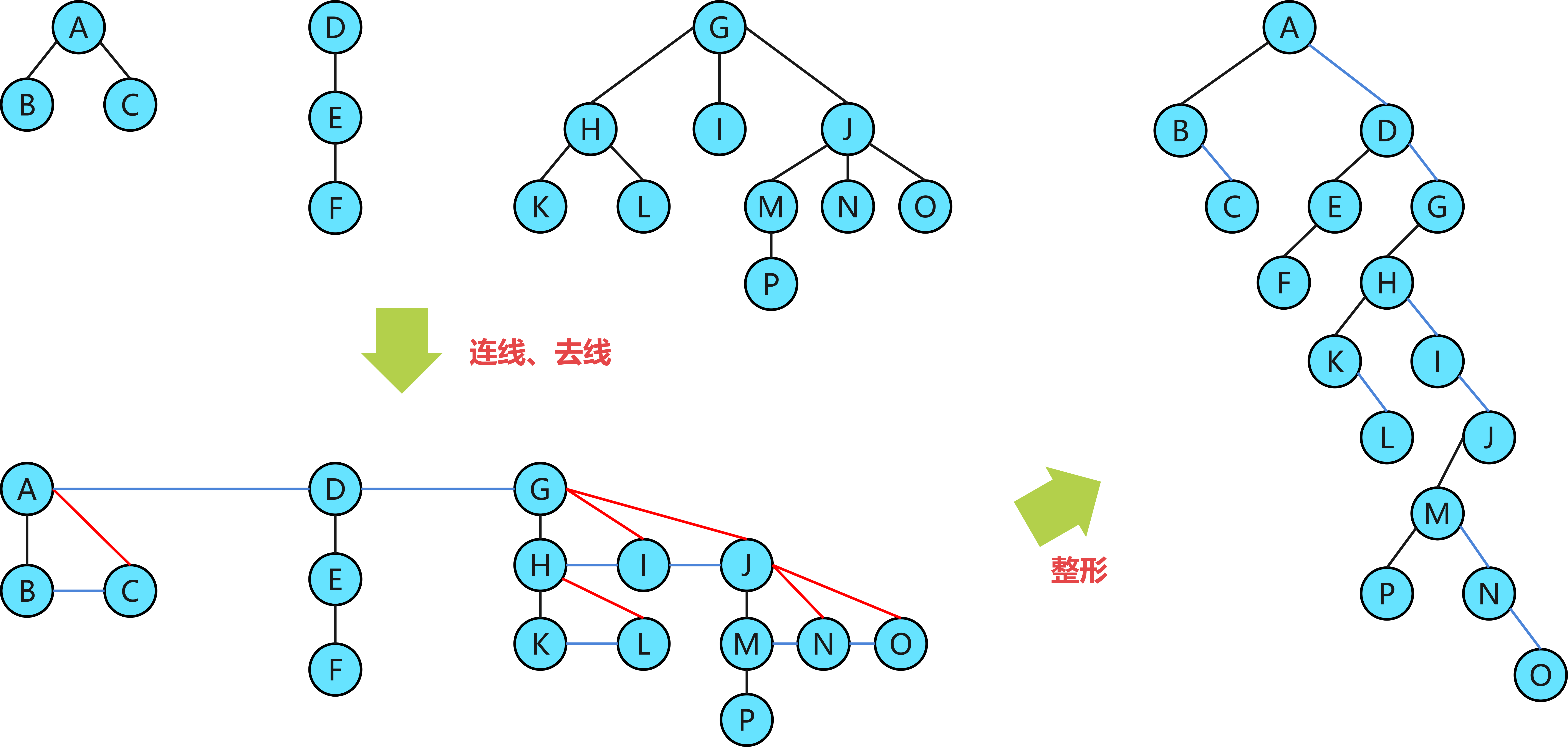
2. 已知某二叉树的先序序列和中序序列分别为ABDEHCFIMGJKL和DBHEAIMFCGKLJ,请画出这棵二叉树,并画出二叉树对应的森林。
答案及解析:
根据二叉树的先序序列和中序序列后,可以唯一确定一颗二叉树(左图)。之后,可以按照二叉树转换为森林的基本流程:整形、连线、去线、整形进行形态变换。即左孩子不变,右孩子变兄弟。
🏷️Project01002
3. 设给定权集 w = {5,7,2,3,6,8,9},试构造关于w的一棵哈夫曼树,并求其加权路径长度WPL。
答案及解析:
🏷️Project01003
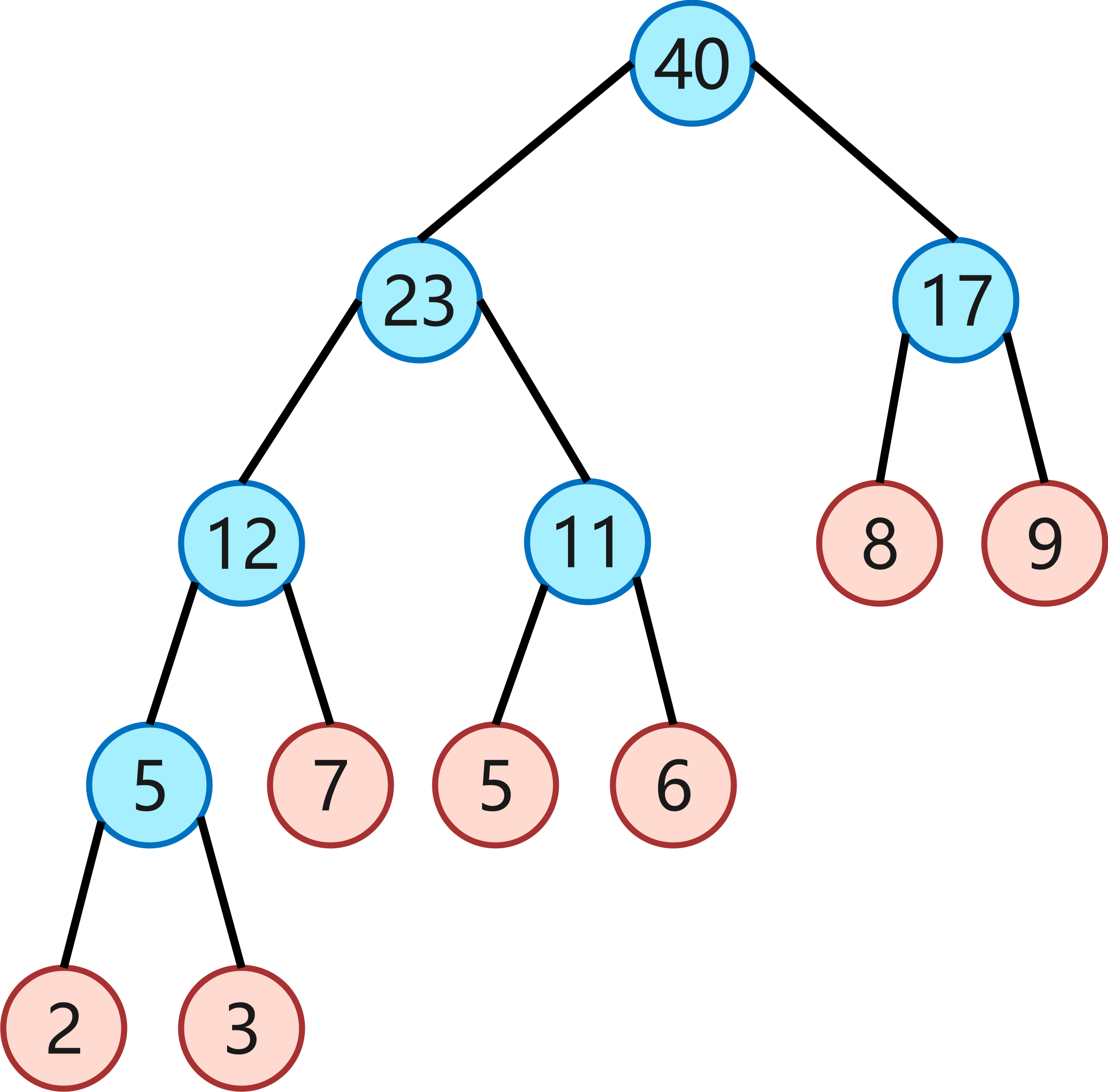
WPL = (2+3)×4 + 7×3 + (5+6)×3 + (8+9)×2 = 108
4. 【2012统考真题】设有6个有序表A,B,C,D,E,F,分别含有10,35,40,50,60和200个数据元素,各表中的元素按升序排列。要求通过5次两两合并,将6个表最终合并为1个升序表,并使最坏情况下比较的总次数达到最小。请回答下列问题:
1) 给出完整的合并过程,并求出最坏情况下比较的总次数。
2) 根据你的合并过程,描述n(n≥2)个不等长升序表的合并策略,并说明理由。
答案及解析:
1). 由于最先合并的有序表在后序的合并中仍然会被使用到,因此应该尽量先合并比较短的表,后合并比较长的表。这个过程类似于利用哈夫曼树构建最短路径的过程,因此可以将表长元素作为权重来进行哈夫曼树的构建。在进行实际表合并的时候,假设两个表表长分别为m和n,则最坏情况需要比较的次数为m+n-1。🏷️Project01004
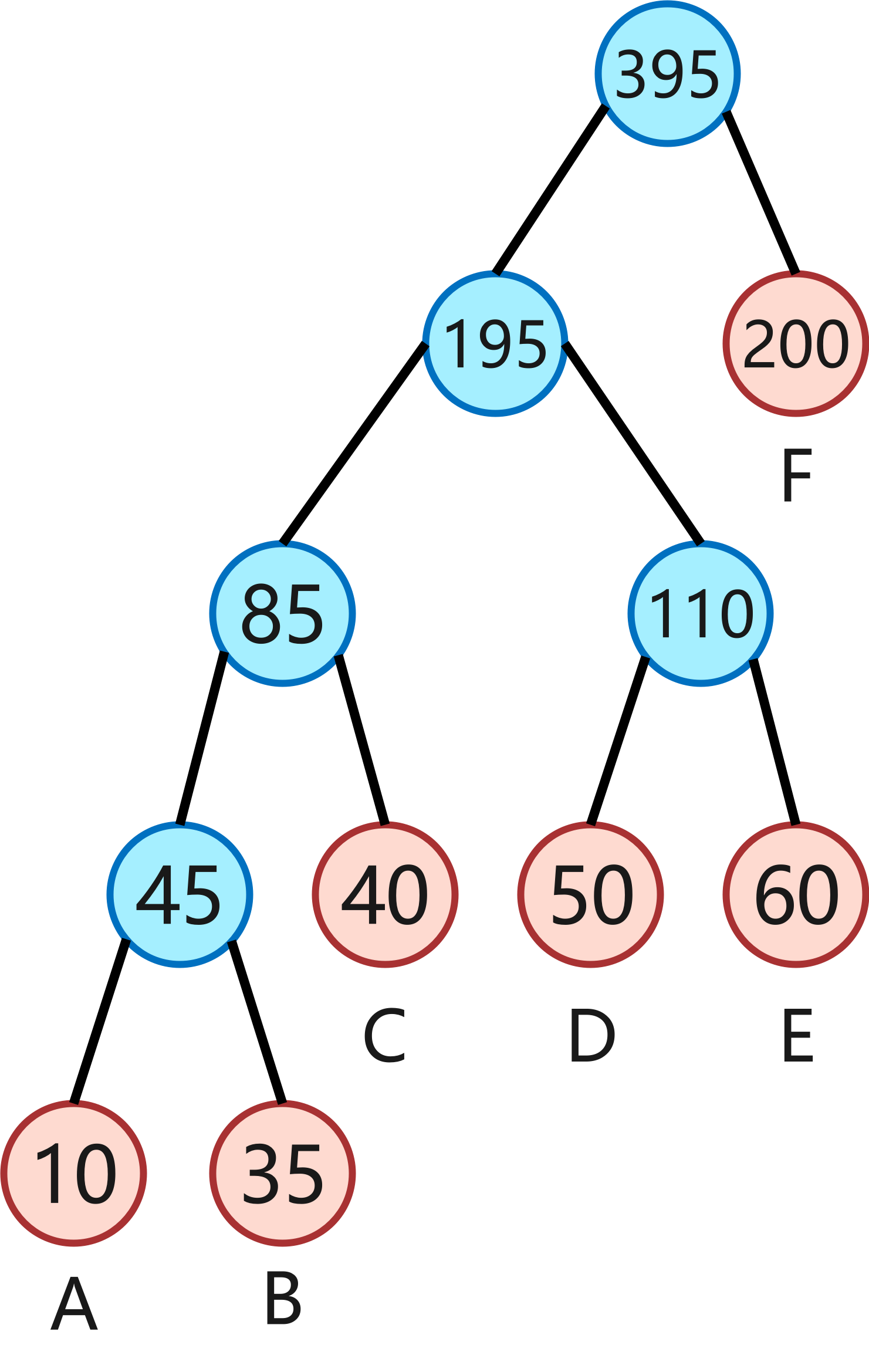
有序表合并过程如图所示,
(1)先对A、B进行合并,生成包含45个元素的列表AB,比较次数=10+35-1=44;
(2)对AB、C进行合并,生成包含85个元素的列表ABC,比较次数=45+40-1=84;
(3)对D、E进行合并,生成包含110个元素的列表DE,比较次数=50+60-1=109;
(4)对ABC和DE进行合并,生成包含195个元素的列表ABCDE,比较次数=85+110-1=194;
(5)对ABCDE和F进行合并生成包含395个元素的列表ABCDEF,比较次数=195+200-1=394。
在合并过程中,比较的总次数为44+84+109+194+394=825。
2). 对多个标进行两两合并时,若表长不同,则最坏情况下总比较次数依赖于表的合并次数。在合并时,为了比较次数更短,应使包含元素越少的元素越先进行合并。此时,可以借助哈夫曼树的思想,依次选择最短的两个表进行合并,此时可获得最坏情况下的比较次数最小的序列。
5. 二叉树按二叉链表形式存储,试编写一个判别给定二叉树是否是完全二叉树的算法。
算法提示(设计思想):
根据完全二叉树的定义,具有n个结点的完全二叉树与满二叉树的编号从1到n的结点一一对应。因此只需要在遍历结点的时候,判定第一个出现的空结点是否就是最后一个结点。具体实现思路如下:
1.采用层次遍历算法,将所有结点加入队列,包括空结点;
2.在进行入队的过程中,依次从队列中取出结点,并判定该结点是否为空结点。若当前结点为非空结点,则将其左、后子树分别加入队列;若为空结点,则继续判断该结点之后是否存在非空结点。若存在,则二叉树不是完全二叉树。
bool isCompleteTree(BiTree BT){
// 在此处填入代码
}
【参考代码】
bool isCompleteTree(BiTree BT){
InitQueue(Q);
if(!BT) // 1. 空树为满二叉树,返回True
return true;
EnQueue(Q, BT); // 2. 将二叉树的根结点BT入队
while(!IsEmpty(Q)){ // 3. 若队列不为空,则依次将队列中结点的子孙结点入队
DeQueue(Q, p); // 3.1 依次从队列中取出结点(树/子树的根结点)
if(p){ // 3.2 若出队结点存在,则依次将其左右孩子入队
//// 3.2.0 注意此处入队时,包括空结点也需要入队
EnQueue(Q, p->lchild); // 3.2.1 左孩子入队
EnQueue(Q, p->rchild); // 3.2.2 右孩子入队
}
else // 3.3 若遇到空结点,则检查空结点之后是否存在非空结点
while(!IsEmpty(Q)){
DeQueue(Q, p); // 3.3.1 顺序出队空结点之后的结点
if(p) // 3.3.2 若后序结点存在,则二叉树不是完全二叉树
return false;
}
}
return true;
}
【选做题】[奖励分:0~1]
已知二叉树以二叉链表存储,编写算法完成:对于树中每个元素值为×的结点,删除以它为根的子树,并释放相应的空间。要求:
1) 给出算法的基本设计思想。
2) 根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
算法提示(设计思想):
- 本题要求删除值为x的结点,同时删除以它为根的子树,并释放空间。可以考虑使用基于二叉链的层次遍历方法来依次将每个结点输入到队列中。
- 在函数定义方面,可以考虑定义两个函数,一个用于删除以BT为根结点的子树,另一个用于遍历子树,并查找与元素值x相等的结点。
- 当某结点的元素值等于x时,就调用删除函数,将该结点的左、右子树都进行删除操作;若不等于则先后入队左、右子树。
// 1. 删除以bt为根的子树
void DeleteXTree(BiTree &BT){
// 在此处填入代码
}
// 2. 在二叉树上查找所有以x为元素值的结点,并删除以其为根的子树
void Search(BiTree BT, ElemType x){
// 在此处填入代码
}
【参考代码】
// 1. 删除以bt为根的子树
void DeleteXTree(BiTree &BT){
if(BT){ // 若二叉树BT存在,则
DeleteXTree(BT->lchild); // 递归删除左子树
DeleteXTree(BT->rchild); // 递归删除右子树
free(BT); // 释放子树BT的存储空间
}
}
// 2. 在二叉树上查找所有以x为元素值的结点,并删除以其为根的子树
void Search(BiTree BT, ElemType x){
BiTree Q[]; // 0. 初始化存储二叉树的队列Q空间
if(BT){
if(BT->data == x){ // 1. 若根结点等于x,则删除根结点及所有子孙结点;否则,继续执行
DeleteXTree(BT);
exit(0);
}
InitQueue(Q); // 2. 初始化队列
EnQueue(Q, BT); // 3. 将根结点入队
while(!IsEmpty(Q)){ // 4. 当队列不为空时,依次执行如下操作
DeQueue(Q, p); // 4.1 出队当前树/子树的根结点
if(p->lchild) // 4.2 处理当前子树根结点的左孩子
if(p->lchild->data == x){ // 4.2.1 若左孩子的元素值等于x,则:
DeleteXTree(p->lchild); // 4.2.1.1 删除该左孩子
p->lchild = Null; // 4.2.1.2 将子树根结点的左孩子指针置空
}
else // 4.2.2 若左孩子的元素值不等于x,则将左孩子入队
EnQueue(Q, p->lchild);
if(p->rchild) // 4.3 处理当前子树根结点的右孩子
if(p->rchild->data == x){ // 4.3.1 若右孩子的元素值等于x,则:
DeleteXTree(p->rchild); // 4.3.1.1 删除该右孩子
p->rchild = Null; // 4.3.1.2 将子树根结点的右孩子指针置空
}
else
EnQueue(Q, p->rchild); // 4.3.2 若右孩子的元素值不等于x,则将右孩子入队
}
}
}
【扩展练习】
1. 编程求以孩子兄弟表示法存储的森林的叶结点数。(只需要写主要功能函数)
算法提示(设计思想):
当森林(树)以孩子兄弟表示法存储时,若结点没有孩子,则它必然是叶子结点;总的叶结点个数是孩子子树上的叶子数和兄弟子树上的叶结点数数之和。因此,可以递归地探测每一个结点,直至它成为没有孩子的叶子结点为止。
// 定义森林的基本数据结构
typedef struct node{
ElemType data;
struct node *lchild, *rightsibling;
}*Tree
int Leaves(Tree f){
// 在此处填入代码
}
【参考代码】
int Leaves(Forest f){
if(f == Null) // 1. 若树为空,则返回0
return 0;
if(f->lchild == Null) // 2. 若结点的孩子域为空,则该结点必是叶子
return 1 + Leaves(f->rightsibling); // 累加叶结点及其兄弟子树中的叶结点数
else // 3. 若结点的孩子域不为空,则
return Leaves(f->lchild) + Leaves(f->rightsibling); // 返回孩子子树和兄弟子树中叶子数之和
}
2. 编写后序遍历二叉树的非递归算法。
算法提示(设计思想):
二叉树的后序遍历所使用的线路与先序、中序是一样。但应注意的是,如果要将某个结点出栈,必须保证该结点的左右孩子已经出栈。具体操作如下:
1.将根压入堆栈,并立即执行输出;
2.从根开始访问左孩子,并将左孩子当作新子树的根,进行入栈,直到左孩子为空,退回到根结点,并输出根结点;
3.当退回到当前子树的根时,访问右孩子。若右孩子为空,则退回到当前子树的根,并将根结点出栈;
4.继续执行步骤3,若右孩子不空,则将右孩子当作新子树的根执行步骤2~3。
void PostOrder(BiTree T)
// 在此处填入代码
}
【参考代码】
void PostOrder (BinaryTree BT) {
InitStack(S); // 1. 初始化堆栈S
BinaryTree *p = BT; // 2.1 初始化工作指针p
BTNode *r =Null; // 2.2 初始化指示指针r,用于指向最近访问过的结点,区分是从左子树返回,还是右子树返回。
while(p || !IsEmpty(S)){ // 3. 后序遍历二叉树,若树不空,则一路向左
if (p) {
Push(S, p); // 3.1 将当前结点压入堆栈
p = p->lChild; // 3.2 左孩子不空,则一直向左走
}
else { // 4. 左孩子为空
GoTop(S, p); // 4.1 读取栈顶子树根结点(暂不出栈,也不输出)
if (p->rchild&p->rchild!=r) // 4.2 若右子树存在,且未被访问,则转向访问右孩子
p = p->rchild;
else{ // 4.3 否则
printf(“%c”, p->data); // 4.3.1 输出当前子树的根结点元素
r = p; // 4.3.2 将指针r指向最近访问过的元素
Pop(S, p); // 4.3.3 将当前栈顶根结点元素进行出栈
p = Null; // 4.3.4 结点访问过后,重置指针p
}
}
3.假设二叉树采用二叉链表存储结构,设计一个非递归算法求二叉树的高度。
算法提示(设计思想):
- 考虑使用层次遍历算法,逐层将结点送入一个队列中进行遍历,当所有结点完成遍历后,输出当前层的编号。
- 设置一个全局参数level,用于记录当前结点所在的层;同时,设置一个last变量指向当前层的最后(最右)一个结点,每次进行层次遍历时均与last指针进行对比,若两者相等则将层数level+1,并使得last指向下一层的最后的结点,直到遍历完成。
- 当遍历某一层的时候,依次将当前访问结点的左、右孩子送入队列。在当前访问结点的队头元素进行出栈时,如果该队头元素等于last指针所指的元素,则它前一个元素的右孩子必定为下一层的最后一个元素。此时指向它的队尾指针即为下一层的最后一个结点。
int BTDepth(BiTree BT){
// 在此处填入代码
}
【参考代码】
int BTDepth(BiTree BT){
if(!BT) // 1. 若二叉树为空,则输出高度0
return 0;
int front = -1, rear = -1; // 2.1 初始化队列的队首指针和队尾指针
int last = 0, level = 0; // 2.2 初始化指向当前层最后一个元素的变量和当前层变量
BiTree p; // 2.3 初始化一个工作指针
BiTree Q[MaxSize]; // 3. 初始化队列Q,元素是二叉树结点指针且有足够的容量
Q[++rear] = BT; // 4. 将根结点加入队列
while(front < rear>){ // 5. 若队列不空,则执行以下操作
p = Q[++front]; // 5.1 将队首元素进行出队
if(p->lchild) // 5.2 若队首元素的左孩子存在,就将左孩子入队
Q[++rear] = p->lchild;
if(p->rchild) // 5.3 若队首元素的右孩子存在,就将右孩子入队
Q[++rear] = p->rchild;
if(front == last){ // 5.4 若当前出队元素已经是最后一个元素,则
level ++; // 5.4.1 将level变量+1
last = rear; // 5.4.2 将last指针指向当前的队尾,即下一层的最后一个元素
}
}
return level; // 6. 遍历完成后,输出level
}
4. 假设二叉树采用二叉链存储结构存储,设计一个算法,求先序遍历序列中第k(1<k<二叉树中结点个数)个结点的值。
算法提示(设计思想):
- 本题使用二叉树的递归遍历方法相对比较容易。考虑设置一个全局变量i,指向先序遍历时,当前访问的结点编号。
- 在遍历过程中,实时比较当前结点i和目标结点k的编号。当i等于k时,输出当前结点;当i不等于k时,按照先序遍历的规则,遍历二叉树;此外,当树为空时,输出特殊字符#
ElemType Find_KNode_Pre(BiTree BT, int k){
// 在此处填入代码
}
【参考代码】
ElemType Find_KNode_Pre(BiTree BT, int k){
int i = 1; // 0. 初始化全局变量i,指向当前操作结点的编号
if(BT == Null) // 1. 若二叉树为空,则输出特殊字符 #
return '#';
if(i == k) // 2. 若编号等于目标编号k,则输出当前元素
return BT->data;
i++;
res = Find_KNode_pre(BT->lchild, k); // 3. 递归遍历左子树,当编号等于目标编号k时,输出当前元素
if(ch != '#') // 若左子树为空,则直接输出#,不为空则返回,并继续遍历右子树
return res;
res = Find_Knode_pre(BT->rchild, k); // 4. 递归遍历右子树,当编号等于目标编号k时,输出当前元素
return res;
}
5.在二叉树中查找值为x的结点,试编写算法打印值为x的结点的所有祖先,假设值为x的结点不多于一个。
算法提示(设计思想):
在树的遍历过程中,最简单的思路是利用非递归的后序遍历,这种方法最后访问根结点,这就意味着当访问值为x的结点时,栈中所有元素均为该结点的祖先。此时只需要依次出栈并输出栈顶元素即可。
// 1. 定义基本数据结构
typedef struct stack{
BiTree BT;
int tag; // tag=0 表示左子树被访问;tag=1表示右子树被访问
} //stack;
// 2. 在二叉树BT中,查找值为x的结点,并打印其所有祖先
void Search(BiTree bt, ElemType x){
}
【参考代码】
// 1. 定义基本数据结构
typedef struct stack{
BiTree BT;
int tag; // tag=0 表示左子树被访问;tag=1表示右子树被访问
} //stack;
// 2. 在二叉树BT中,查找值为x的结点,并打印其所有祖先
void Search(BiTree BT, ElemType x){
stack s[]; // 1. 初始化栈,用于存储树的结点
top = 0;
while(BT != Null || top>0){ // 2. 若树不为空,则执行判断
while(BT != Null && BT->data != x){ // 2.1 当前子树的根结点不等于目标值x时,
s[++top].t = BT; // 2.1.1 将当前子树的根结点入栈
s[top].tag = 0; // 2.1.2 修改tag标识为0
BT = BT->lchild; // 2.1.3 开始沿着左分支一路向下
}
if(BT != Null && BT->data == x){ // 2.2 若找到x,则输出x及该以该节点的祖先元素
print("所查结点的所有祖先结点值为:\n");
for(i=1; i<=top; i++) // 2.2.1 遍历并输出栈中所有元素,即当前结点的所有祖先
print("%d", s[i].t->data);
exit(1); // 2.2.2 退出
}
while(top != 0 && s[top].tag == 1) // 2.3 执行退栈
top--;
if(top != 0){ // 2.4 沿右分支向下遍历
s[top].tag = 1; // 2.4.1 修改tag标识为1
BT = s[top].t ->rchild; // 2.4.2 开始沿着右分支一路向下
}
}
}
6.写出在中序线索二叉树里查找指定结点在后序中的前驱结点的算法。
算法提示(设计思想):
- 对于后序遍历来说,其访问顺序为左右根。因此,若结点p有右孩子,则右孩子是p的前驱;若结点p没有右孩子,但是有左孩子,则左孩子是结点p的前驱。
- 当结点p左、右孩子都不存在时,需要考察该结点在中序线索树中的前驱线索指针。假设存在结点f是p的祖先,根据中序遍历的规则左根右,若p是f的右孩子,并且f的左孩子存在,则p的前驱就指向f的左孩子;若p本身就是f的左孩子,则p的前驱就应该是f的双亲的左孩子,此时若f的双亲的左孩子存在,则该结点即为p的的前驱,若f的双亲的左孩子不存在,则需要一直顺着结点的双亲探测下去,直到找到第一个包含左孩子的结点,此时将该左孩子设置为结点p的前驱。
- 还有一种特殊情况,若p时中序遍历的第一个结点,即根结点的左孩子,或者唯一的根结点,则该结点没有前驱。
BiThrTree InPostPre(BiThrTree t, BiThrTree p){
// 在此处填入代码
}
【参考代码】
BiThrTree InPostPre(BiThrTree t, BiThrTree p){
BiThrTree q; // 0. 定义指针q用于保存p的前驱
if(p->rtag == 0) // 1.1 若结点p有右孩子,则右孩子就是p的前驱
q = p->rchild;
else if(p->ltag == 0) // 1.2 若结点p没有右孩子,但有左孩子,则左孩子就是p的前驱
q = p->lchild;
else if(p->lchild == Null) // 2. 若p是中序遍历的第一个结点,则p不存在前驱
q = Null;
else{
while(p->ltag == 1 && p->lchild != Null) // 3. 若p的左右孩子都不存在,则顺着线索向上查找p的祖先的左子树。
p = p->lchild;
if(p->ltag == 0) // 3.1 找到某个祖先的存在左孩子时,将该结点作为p的前驱
q = p->lchild;
else // 3.2 若p的所有祖先中,均没有左孩子,则p没有前驱,即p就是第一个输出的结点
q = Null;
}
return q;
}
7.【2014统考真题】二叉树的带权路径长度(WPL)是二叉树中所有叶结点的带权路径长度之和。给定一棵二叉树T,采用二叉链表存储,结点结构为left|weight|right。其中叶结点的weight域保存该结点的非负权值。设root为指向T的根结点的指针,请设计求T的WPL的算法,要求:
1)给出算法的基本设计思想。
2)使用C或C++语言,给出二叉树结点的数据类型定义。
3)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。
算法提示(设计思想):
0. 求二叉树的带权路径长度WPL,实际上就是计算每个叶结点的深度与叶结点权值的积的累加。
- 使用先序遍历对树进行遍历,定义个静态变量static来统计wpl的值,同时将每个结点的深度作为递归函数的参数进行传递。
- 若结点是叶子结点,则变量wpl加上该结点的深度与权值之积;
- 若该结点是非叶结点,则左子树不为空时,对左子树调用递归算法,右子树不为空时,对右子树调用递归算法,深度参数为本结点的深度+1。
- 遍历结束后,返回wpl值。
typedef struct BiTNode{
// 在此处填入代码
}BiTNode, *BiTree;
bool WPL(BiTree root){
// 在此处填入代码
}
【参考代码】
typedef struct BiTNode{
int weight;
struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;
int WPL(BiTree root){
return wpl_PreOrder(root, 0);
}
int wpl_PreOrder(BiTree root, int deep)
static int wpl = 0; // 1. 定义存储wpl的静态遍历wpl
if(root->lchild == NULL && root->rchild == NULL) // 2. 若结点为叶子,则累积wpl
wpl += deep*root->weight;
if(root->lchild != Null) // 3. 左子树不空,递归遍历左子树
wpl_PreOrder(root->lchild, deep+1);
if(root->rchild != Null) // 4. 右子树不空,递归遍历右子树
wpl_PreOrder(root->rchild, deep+1);
return wpl; // 5. 整棵树完成后,输出wpl
}